大模型在货运取消单判责上的应用探索
货拉拉作为货运交易买卖平台,需要对司机行为进行规范,提升服务质量。所以我们会对取消单进行事后判责找出取消的责任方,从而给出对应的补偿或者教育措施。
下面是一个例子:用户备注了尾板需求。司机抢单后以尾板为由加价100元,被用户拒绝,导致取消单。

判责标准有几十个场景,包含上百条判责细则。判责标准涉及司机、用户、货物三者大量不同维度的信息。同时业务还会定期调整细则定义,复杂度高。
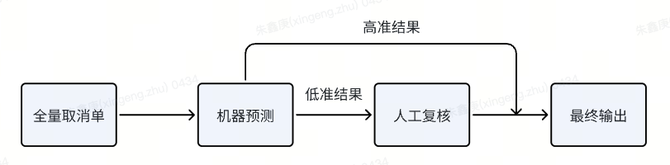
所有取消单都会先经过机器,机器预测命中哪些细则,高准确率细则会直接输出,低准确率细则会经过人工复核再输出。
1. 判责标准粒度细、数量多、难度大。在有一定标注人力的情况下,如何更高效的去提升效果。另外,如何与线上人工判责的数据来进行有效融合,让机器效果能持续的迭代,也是重要的问题。
2. 可解释性要求高。判责结果直接和司机、用户的体验有关。如何在效果和体验上做平衡,需要持续思考。
3. 多模态特征。判责标准涉及语音、照片、文本、位置、时间、费用、轨迹等多维度特征。怎么样更好的利用这一些信息,对工程、算法都是很大的挑战。
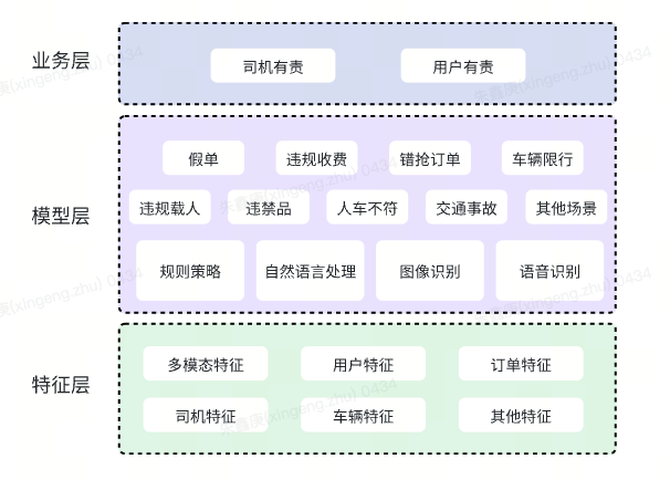
2. 模型层:通过规则策略、自然语言处理、图像识别、语音识别等不同方法,预测不同的判责场景和细则。
近年来,随着大模型技术的加快速度进行发展,其在复杂上下文理解、逻辑推理以及数值计算等方面展现出了强大的能力。这些技术特点恰恰是我们解决取消单判责难题所需要的。
案例:“用户让司机帮忙搬运,双方在通话中反复的对搬运费讨价还价,最后未达成一致,造成订单取消。”
我们需要分析双方提出的搬运费是不是满足平台制定的费用标准。而费用标准应该要依据搬运的物品、重量、搬运距离/楼层等综合计算。
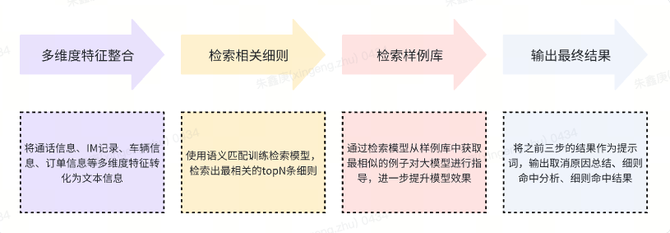
1. 将多维度的特征信息统一转化为文本信息。这一些信息包括但不限于司机与用户间的通线. 使用文本信息来检索最相关的判责细则。由于判责标准包含上百条细则,我们开发了一个检索模型,能够筛选出与当前情况最相关的topN条细则。
3. 为了提高模型的准确性,我们还建立了一个样例库,并通过另一个检索模型根据当前情况找出相似的历史案例。
4. 最后,将转化后的文本信息、检索到的判责细则和相关样例一同送入大模型进行推理分析,得出最终的判责结果。

司用双方会通过电话做沟通,通话信息是内容最丰富、最关键的数据;照片包括了装货、卸货的照片,司机在路上碰到了某些问题,也会通过照片进行真实性验证。用户会在备注中写明要求,有时也会通过IM与司机进行沟通。
车辆的参数信息,包括尺寸、型号、载重、座位数量等;同时车辆是否有高栏、尾板等配备。
司机接单时的位置、装货地/卸货地的位置,三者间的距离,对应的费用;导航信息与车辆行驶轨迹可用来判断行驶线路是不是合理,司机是否有按时到达了装货地、卸货地;用户在订单上是否有搬运、跟车人数等需求。
判责标准涵盖了上百条细则定义,我们没办法一次性将所有细则都放入提示词,这样做会显著影响模型的判断效率。因此,我们设计了一个高效的检索模型,旨在从众多细则中迅速获取最大有可能与当前文本信息相关的topN条细则。
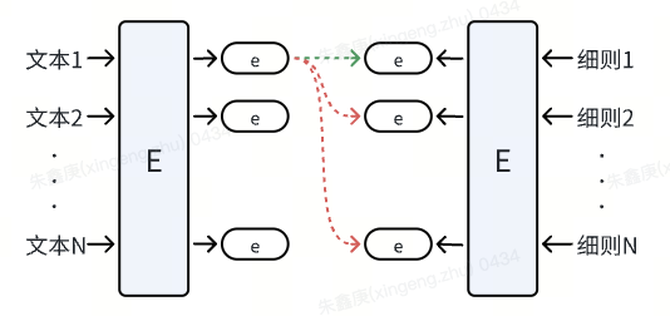
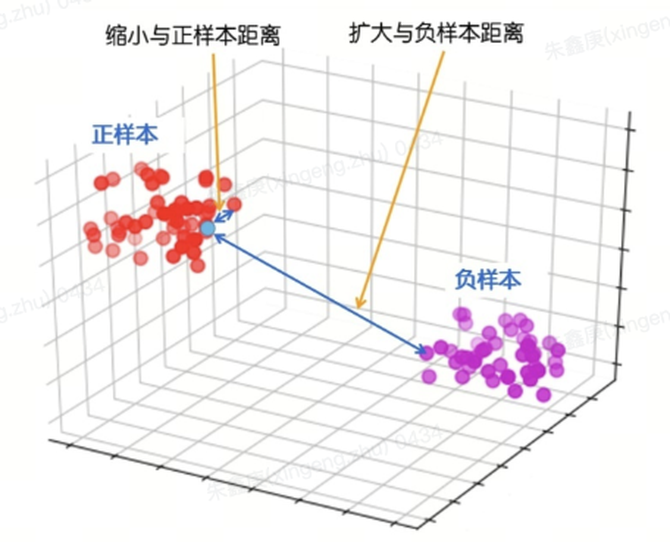
我们首先将文本信息和细则定义通过同一个encoder进行编码,转化为embedding向量。在这样的一个过程中,当前文本对应的细则被视为正样本对,而其他与此文本不相关的细则被视为负样本对。
通过模型优化,我们拉近正样本对间的距离,同时推远负样本对间的距离,从而在向量空间中形成清晰的区分。
当需要进行预测时,我们仅需输入相应的文本信息,模型便能迅速从细则库中选出距离最近的topN条细则。
为了逐步提升模型的效果,我们预先构建了一个丰富的样例库,并采用了RAG的思路。RAG框架允许模型在生成内容时实时引入外部知识,从而使得生成的内容更加准确且信息丰富。
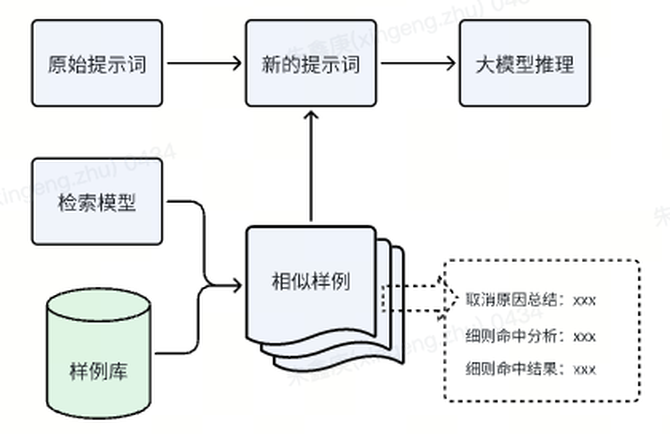
在我们的样例库中,每个样例都记录了文本信息、取消原因总结、细则命中分析以及细则命中结果。当遇到新的判责文本信息时,我们会通过另一个专门设计的检索模型,从样例库中快速检索出多个相似样例。
由于文本信息通常较长且包含大量细节,我们在将样例引入提示词时会去除这部分内容,只保留取消原因总结、细则命中分析和细则命中结果。随后,我们将这些样例信息与原始提示词进行拼接,形成一个更加清晰且有明确的目的性的提示词。
通过引入RAG框架对大模型进行指导,我们得知模型的精度得到了显著提升。此外,我们还持续将badcase添加到样例库中,以便模型能够在未来的判断中避免犯下相同的错误,以此来实现持续优化。

将任务要求、多维度信息、细则定义、参考样例组合成一整个提示词,送入大模型进行最后的推理。形式类似上图。
我们在输出结果中加入了取消原因总结、细则命中分析作为中间过程,一是使用COT的模式去缓解大模型的幻觉问题,让输出结果更稳定。二是提供了更多可解释的信息,便于业务方去提升司机体验。

1. 司用双方的通话信息作为判责中最重要的依据,目前通过ASR转译后送入大模型,ASR的效果限制了大模型的能力上限。
2. 大模型的效果离人工还有距离,如何结合线上人工判责记录,持续提升效果。
3. 我们将所有特征转为文字后输入大模型,是否有其他更好的结合照片、地图等信息的方式。
这些问题都要求我们进一步的研究。货拉拉也会在取消单判责上继续努力,给司机和用户所带来更好的服务体验。